Natural language processing consultancy

“Thomas has been fantastic with his approach, and the deliverables of our project. He's really good to work with. 100% recommend.”
“We really enjoyed working with them and interacting with the high-quality Dash Apps they are building. They super responsive and a pleasure to work wtih.”





Blog
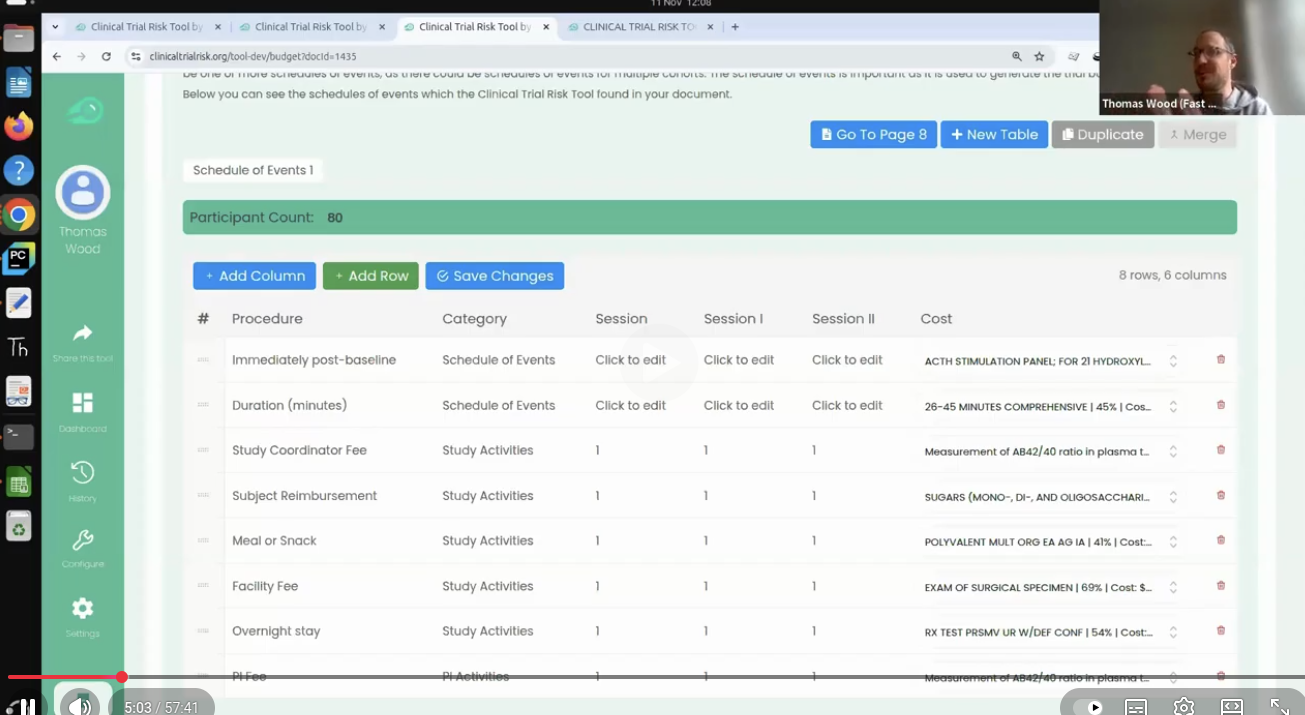
Fast Data Science Ltd’s flagship AI platform, the Clinical Trial Risk Tool, has been accepted as a supplier on the UK Government’s G-Cloud 15 framework.

We are pleased to announce that Thomas Wood, director of Fast Data Science, will be appearing as a panelist at the Bond Solon Expert Witness Conference on 6 November 2026 at Church House, Westminster in London. This follows Thomas’s recent appearance at the Ireland’s Expert Witness Conference on 20 May 2026.
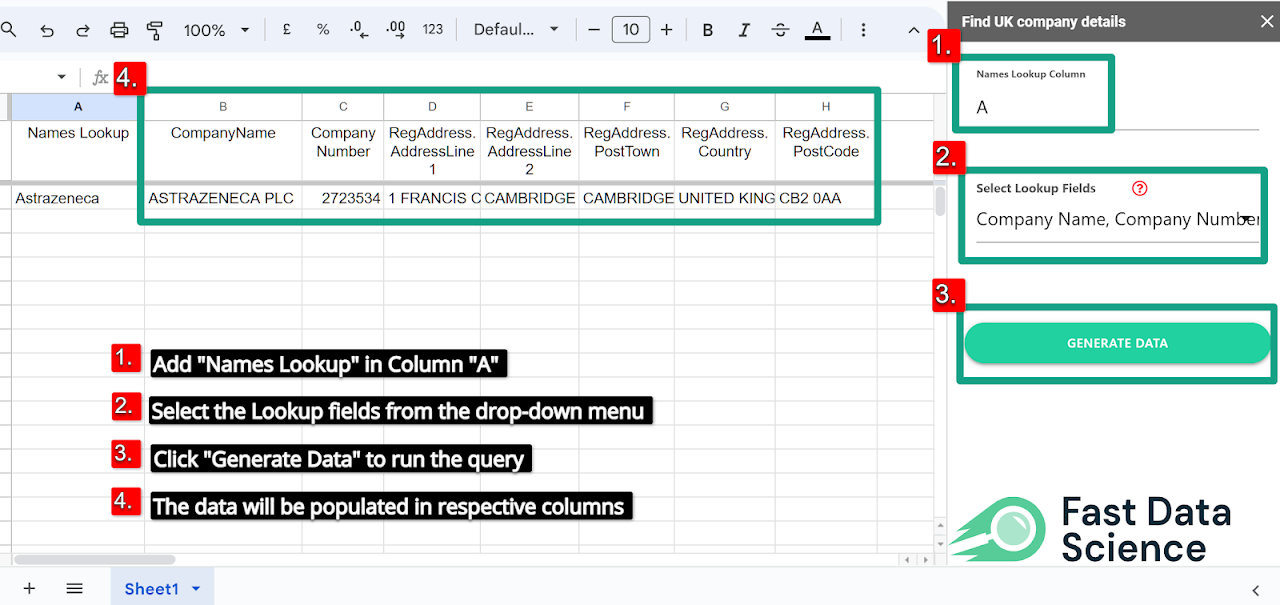
Fast Data Science are pleased to announce we have updated the UK Company Details Google Sheets™ plugin. The plugin allows you to retrieve details such as company number, incorporation date, address, and directors’ details from Companies House (the UK company registry) and automatically populate them in columns of a Google Sheets™ spreadsheet.
5 out of 5 stars
“We will not overload you with academic credentials, buzzwords and jargon, but you can be sure that the solutions that we present to you will be practical and easy to understand, and that we will be able to deliver real value for your company. We can supply references on request.”

What we can do for you